Je voulais un transcripteur de réunions gratuit qui ne coûte rien. Voici les murs que j'ai pris en le construisant.
Le vrai parcours derrière un transcripteur de réunions gratuit et sans inscription : chaque mur, dans l'ordre, du plan que j'avais verrouillé à l'hybride à 75 $ que j'ai livré, y compris les deux que je n'ai jamais franchis.
Salut !
Je m’appelle Lambert, et je dirige le growth chez Kai. Je ne suis pas ingénieur.
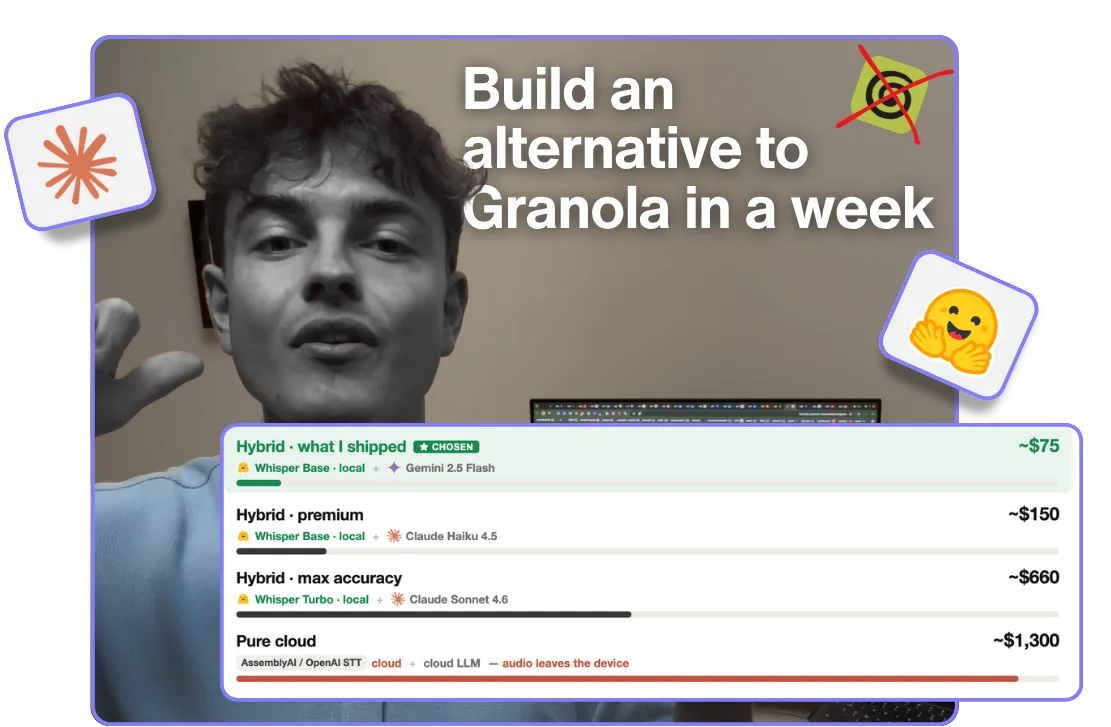
Voici le plan : un transcripteur de réunions qui tourne entièrement dans ton navigateur. Une alternative à Granola. Pas de connexion, pas de téléchargement, pas d’inscription. Tout en local, donc ton audio ne quitte jamais ton appareil, et ça me coûte quasiment rien à faire tourner.
J’ai obtenu presque tout ça. Mais pas tout. La partie « ne coûte rien » a cassé en premier : construit de la manière évidente, sur une API de transcription cloud, ce truc m’aurait coûté environ 1 365 $ par mois. Je l’ai livré pour environ 75 $. Et il ne marche toujours pas sur ton téléphone.
Ce n’est pas la version propre. C’est le chemin que j’ai vraiment parcouru, mur par mur, dans l’ordre où je les ai pris, y compris les deux que je n’ai jamais franchis. Si tu t’apprêtes à construire un truc dans le genre, prends ça comme une carte des mines. Je l’ai construit en une semaine à notre hackathon de Zurich, et le code était la partie facile.
C’est parti.
Le plan que j’avais verrouillé avant de commencer (et pourquoi il était faux)
Quelques jours avant le hackathon, je me suis posé avec Jim, notre lead growth, et on a écrit le cahier des charges en direct. Il était propre. Whisper pour la transcription, entièrement sur l’appareil. Un LLM local (Llama 3.2 3B, dans le navigateur) pour le résumé, pour que rien ne quitte jamais la machine. Les modèles cloud explicitement écartés. Une démo de 30 minutes, verrouillée derrière un email. Fonctionnel d’abord, joli plus tard.
Deux de ces verrous étaient morts en une semaine. Garde ce plan en tête, parce que tout le reste, c’est moi en train de le démonter.
Mur 1 : le navigateur n’entend pas l’appel
La toute première chose qui a cassé, c’est l’évidence. Sur un Mac, une page web peut capter ton micro et l’audio d’un onglet Chrome, mais elle ne peut pas capter le son qui sort d’une application native, le client de bureau Zoom ou Teams. Mets un casque et l’autre côté de l’appel disparaît. C’est une restriction de l’OS, pas un bug. Aucune ligne de code maligne ne corrige ça.
J’ai donc arrêté de traiter ça comme un truc cassé. J’ai assumé tout le produit autour : ce serait une démo honnête, micro d’abord, de ce que fait notre application, et j’ai écrit la limite directement dans le texte au lieu de la cacher. (C’est aussi pour ça que deux choses existent : cet outil web, et une extension Chrome séparée qui, elle, peut capter l’audio d’un onglet.) Nommer la limite à voix haute, c’est ce qui transforme « c’est cassé » en « c’est honnête ».
Mur 2 : personne ne télécharge 80 Mo chez un inconnu
Pour transcrire sur l’appareil, j’utilise Whisper, exécuté dans le navigateur via Transformers.js de Hugging Face (le modèle Xenova/whisper-base). Ça fait environ 80 Mo au premier chargement.
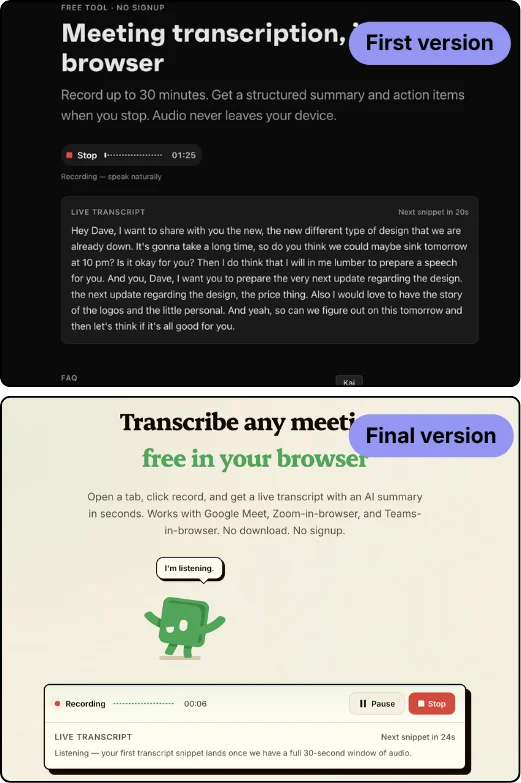
Jim a dit tout haut ce que tout le monde pense en testant une première version : « si je vais sur une page web random et qu’on me demande de télécharger un truc, je me dis non, je sais pas qui vous êtes. » Il a raison. Ma première version affichait une barre honnête « chargement 80 Mo… », et une barre de progression honnête sur une page anonyme, c’est un tueur de conversion.
C’est le premier endroit où le travail a cessé d’être « écrire du code » pour devenir « piloter le modèle ». J’ai enchaîné les allers-retours avec Claude jusqu’à ce que le téléchargement disparaisse derrière le bouton Enregistrer. Maintenant tu cliques sur enregistrer, un court écran s’affiche un instant pendant que le modèle se charge, et tu enregistres en environ une seconde. Tu le charges une seule fois. À moins d’effacer tes données, tu n’attends plus jamais. Les 80 Mo sont réels. Tu ne les sens juste jamais.
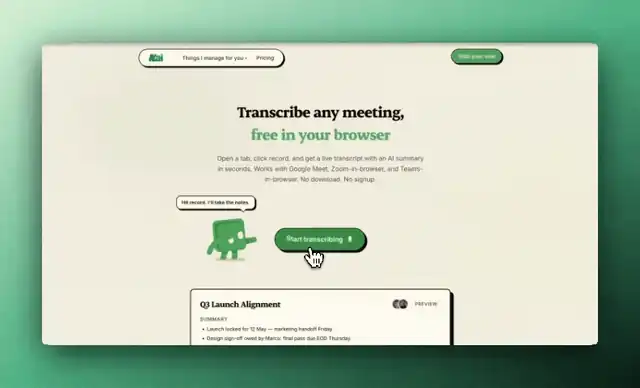
Mur 3 : l’outil « gratuit » qui ne l’était pas (mon plan tout-local meurt)
Tu te souviens du plan verrouillé, celui où le résumé tourne aussi en local et où le tout ne me coûte rien ? Il est mort ici, quelques jours après le début.
Faire tourner le modèle de résumé sur l’appareil, ça veut dire le livrer à chaque utilisateur : Llama 3.2 3B, c’est un téléchargement de 1,78 Go. Après que le Mur 2 venait de m’apprendre que 80 Mo font déjà fuir les gens, 1,78 Go était hors de question, et la qualité du résumé local était de toute façon en dessous de ce que produit notre app. Alors j’ai modélisé chaque option avec de vrais chiffres au lieu de décider au feeling :
| Architecture | Transcription · Résumé | $/session | $/mois* | Audio sur l’appareil |
|---|---|---|---|---|
| Tout local | Whisper Base (local) · Llama 3.2 3B (local) | ~$0 | ~$0** | Oui |
| Hybride · le moins cher | Whisper Base (local) · Gemini 2.5 Flash Lite | $0.003 | ~$45 | Oui |
| Hybride · ce que j’ai mis en prod | Whisper Base (local) · Gemini 2.5 Flash | $0.005 | ~$75 | Oui |
| Hybride · premium | Whisper Base (local) · Claude Haiku 4.5 | $0.010 | ~$150 | Oui |
| Hybride · précision max | Whisper Turbo (local) · Claude Sonnet 4.6 | $0.044 | ~$660 | Oui |
| Tout cloud · AssemblyAI | AssemblyAI · Claude Haiku 4.5 | $0.083 | ~$1,245 | Non |
| Tout cloud · OpenAI STT | gpt-4o-mini-transcribe · Gemini 2.5 Flash Lite | $0.091 | ~$1,365 | Non |
* Modélisé sur une base illustrative de 500 sessions/jour, session de 30 minutes en moyenne, environ 5-6k tokens en entrée et 1-1,5k en sortie par résumé. Prix en date de juin 2026. ** Le calcul en local est gratuit ; le seul vrai coût du tout local, c’est de livrer le bundle de 1,78 Go (Whisper Base plus le modèle de résumé Llama), ce qui revient à ~$0 sur un CDN de modèles gratuit comme Hugging Face. Je l’ai écarté pour la taille du téléchargement, pas pour le coût.
La partie chère, c’est la transcription dans le cloud. Au moment où tu envoies de l’audio à une API speech-to-text payante, tu es à bien plus de mille dollars par mois. Fais tourner la transcription sur l’appareil et ce coût tombe à zéro. La logique de confidentialité et la logique de coût se sont révélées être exactement la même décision : garder l’audio sur l’appareil, garder la facture raisonnable.
J’ai donc abandonné le rêve du « tout local » et livré l’hybride : Whisper en local pour la transcription, Gemini 2.5 Flash pour le résumé, un modèle cloud rapide et pas cher, largement assez bon pour des notes de réunion. Voici le compromis, dit clairement : ton audio ne quitte jamais ton appareil, mais le texte de la transcription fait un seul aller-retour vers Gemini pour le résumé. Le tout local garde même le texte sur l’appareil ; le tableau montre pourquoi je ne l’ai pas pris. Je n’ai pas eu mon outil gratuit. J’en ai eu un à 75 $, parce qu’une expérience fluide voulait dire payer cet aller-retour.
Mur 4 : un endpoint anonyme qui coûte de l’argent se fait abuser
À la seconde où cet aller-retour cloud s’est retrouvé derrière un endpoint public et sans connexion, un nouveau mur est apparu. Un endpoint ouvert qui appelle un modèle payant, c’est quelque chose que les gens vont scraper pour faire exploser ta facture, et un collègue qui bosse sur l’app l’a signalé avant moi.
La parade est en couches, et ennuyeuse. La clé et le prompt restent côté serveur, donc le navigateur ne voit que le résultat, jamais le modèle ni les identifiants. L’endpoint est cantonné à une seule tâche, impossible de le détourner pour autre chose. Et il y a des limites en dessous : un plafond de dépense et du throttling pour qu’aucune source ne puisse le marteler. Je ne publie pas les seuils exacts, c’est tout l’intérêt de les avoir.
Rien de tout ça n’apparaît dans l’interface. L’essentiel de « livrer un outil IA gratuit », c’est exactement ça, le mur ingrat dont personne ne parle.
Mur 5 : j’ai construit un paywall, puis je l’ai arraché
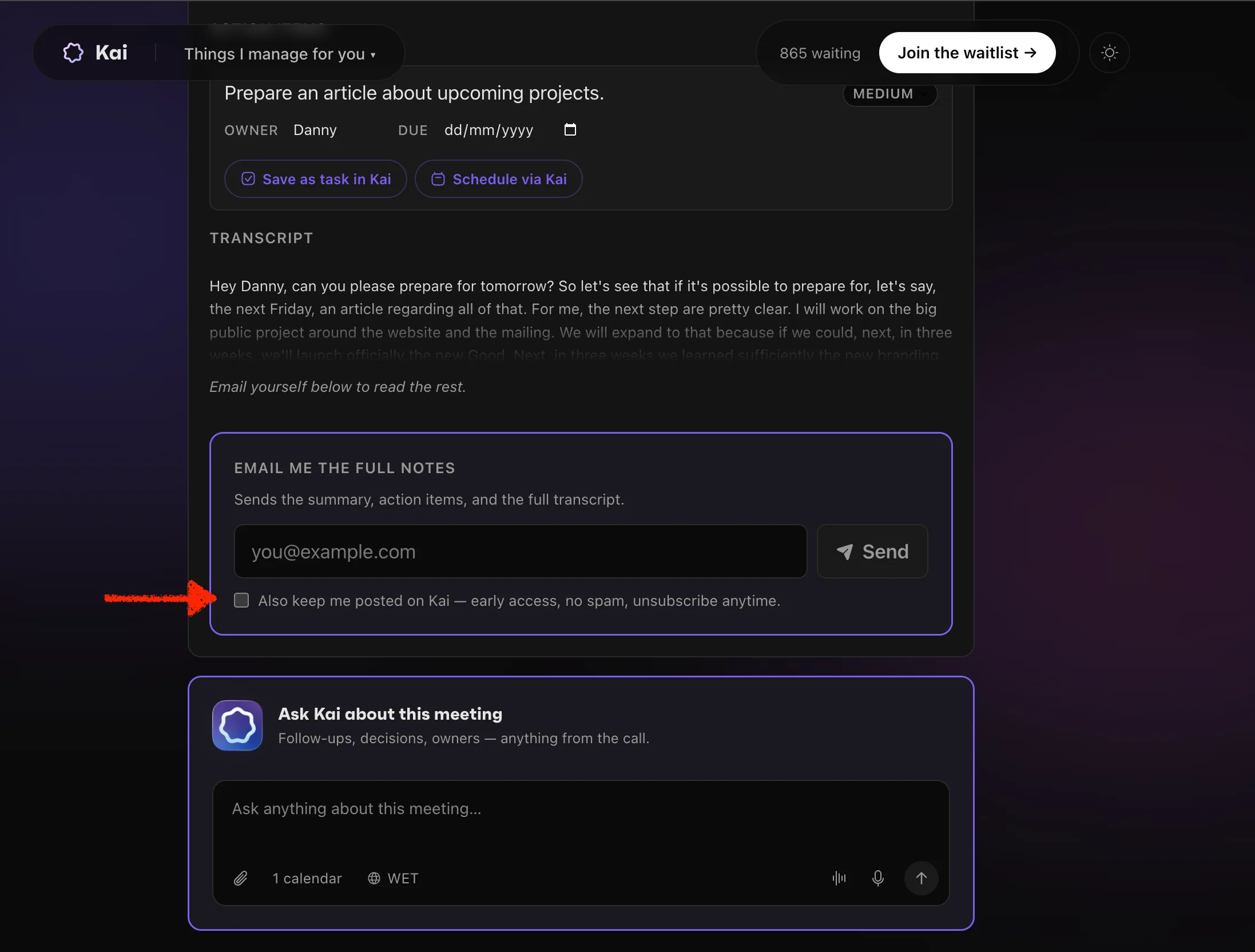
Celui-là, je veux être honnête dessus, parce que la version propre le cacherait. Le 5 mai, j’ai littéralement livré le grand classique du growth : un aperçu de transcription flouté, une carte email façon paywall, le verrou complet. Il fallait donner quelque chose pour voir tes notes.
Trois jours plus tard, dans notre débrief, David l’a tué en une phrase : « si c’est un outil gratuit, c’est quoi leur vrai produit ? » L’argument a fait mouche. Un verrou fait passer un outil gratuit pour une version dégradée d’un truc que tu ne vois pas. Alors je l’ai arraché. L’outil est devenu une démo complète et gratuite : utilise-le quand tu veux, envoie les notes à toi-même ou à un collègue, on ne stocke rien.
La valeur n’a pas disparu, elle s’est déplacée vers la profondeur. Sauvegarder chaque réunion, pousser les actions à mener dans ton agenda, discuter avec une réunion passée, rédiger le suivi. C’est ce que fait l’app, et c’est là qu’une transcription gratuite cesse de suffire. Sous-histoire honnête : la plupart de ces passerelles sont mockées dans l’outil gratuit et redirigent vers l’inscription, parce que le vrai backend n’était pas encore construit. Liste tout ce que tu veux, mocke ce que tu ne peux pas encore construire. C’est le même pari que j’ai fait avec mes outils SEO gratuits : donne la valeur, convertis sur la profondeur, pas sur un verrou.
Envie de voir ? Ouvre un onglet et parle pendant dix secondes : hirekai.ai/tools/meeting-transcription.
Mur 6 : le mobile, celui que j’ai perdu
Tous les murs n’ont pas de porte. L’outil est conçu pour le SEO, et une page qui casse sur mobile est un signal d’alerte pour Google, donc je ne pouvais pas juste l’ignorer. J’ai essayé. J’ai perdu.
Mon premier réflexe a été d’accuser WebGPU, mais Safari sur iOS embarque désormais WebGPU, donc ce n’était pas ça. Ensuite j’ai construit un modèle de repli plus léger (Moonshine) spécialement pour faire marcher le mobile. Ça a quand même planté. Voici ma propre note de test sur appareil, telle quelle, parce que c’est la preuve :
Première tentative : barre de progression bloquée sur « Chargement du modèle de transcription — 99 % » pendant 3 minutes et plus, aucune erreur, aucune reprise. Deuxième tentative, après un hard refresh : le modèle s’est chargé, l’enregistrement a démarré, le micro a capté la voix pendant ~4 s, puis Chrome iOS a tué l’onglet sur une erreur mémoire. Même crash sur un vrai iPhone, pas un cas tordu.
Le vrai mur, c’est la mémoire. Charger le modèle et faire tourner l’inférence dépasse ce qu’iOS accorde à un seul onglet de navigateur, et l’onglet se fait tuer, même avec le modèle plus léger. Une journée entière avec Claude, et je n’ai pas réussi à passer.
Donc je ne suis pas passé. Je ne peux pas tricher avec la physique. C’est meilleur sur Chrome desktop, les utilisateurs mobile vont sur l’app, et je l’ai dit exactement comme ça dans le texte. Deux choses m’ont sauvé ici : tester sur un vrai appareil plutôt que sur le simulateur (la seule raison pour laquelle je le sais), et savoir ce qu’il ne faut pas livrer, parce que prétendre « ça marche sur mobile » alors que ça plante m’aurait coûté bien plus que la limite honnête.
Mur 7 : le bug « trivial » qui n’en était pas (le refresh efface tout)
Le dernier mur est de ceux que personne n’appelle un mur. Il est venu d’un vrai retour : tu rafraîchis la page et toute ta transcription a disparu. De la friction pure, au pire moment.
Il me fallait de la persistance sans backend, sans comptes, sans rien stocker sur nos serveurs. J’ai regardé IndexedDB (surdimensionné pour une seule transcription) et les fragments d’URL (une fuite de confidentialité, ta réunion dans la barre d’adresse). J’ai atterri sur localStorage : une transcription, suppression explicite uniquement. « Stocké uniquement sur ton appareil » est devenu à la fois la persistance et l’argument de confidentialité.
Ça a ouvert toute cette couche qui n’est pas vraiment des fonctionnalités : une animation de chargement pendant que le résumé s’écrit, pour que l’attente paraisse vivante, une bannière « reprends là où tu t’es arrêté ». Rien de tout ça ne va sur une landing page. Mais c’est pour ça que les gens restent sur la page, et pour quelqu’un du growth ça compte doublement, parce que le temps passé sur la page est un signal que Google récompense et il indique à quiconque atterrit là que le vrai produit est construit avec soin. Le même instinct que mon playbook de sites AI-native. C’est le mur que j’avais le plus sous-estimé, celui qui avait l’air de rien.

Ce qui a vraiment bouffé la semaine
Le MVP a été la partie peu chère. J’ai livré ça en une semaine sans être ingénieur, et la construction elle-même a rarement été le goulot d’étranglement.
Ce qui a mangé la semaine, ce sont les deux choses que tu ne peux pas confier au modèle : le piloter quand il part de travers (la journée mobile, le combat du téléchargement invisible), et le goût de savoir quels détails UX comptent vraiment. C’est la plus grosse courbe d’apprentissage Claude Code que j’aie eue depuis que j’utilise des LLM, et presque rien là-dedans n’était de l’écriture de code. Il y a quelques années, l’artisanat, c’était construire le MVP. Aujourd’hui le MVP est presque gratuit, et l’artisanat s’est déplacé : vers le pilotage de l’IA, et vers la maîtrise de l’expérience autour.
Je voulais un outil gratuit et entièrement local. J’ai livré un hybride à 75 $ qui perd sur mobile. Chaque mur entre ces deux-là, c’est la vraie carte. Six d’entre eux, je les ai contournés en changeant le produit. Un, je suis encore derrière.
Essaie-le / À propos de Kai
Tu peux essayer l’outil ici. Ouvre un onglet, appuie sur enregistrer, parle pendant dix secondes. Meilleur sur Chrome desktop.
Kai est un assistant IA qui fait des choses pour les gens, construit par l’équipe derrière Morgen. Les outils gratuits comme celui-ci font partie de notre façon de penser le growth. L’extension Chrome qui l’accompagne, qui capture tout l’audio d’un onglet (la chose que le navigateur ne pouvait pas faire, au Mur 1), est un projet à part.
Suis l’aventure :
Ce n’est pas de la théorie. C’est une semaine documentée à construire un vrai outil, y compris les parties qui ont cassé. Si ça t’a été utile, partage-le avec quelqu’un qui s’apprête à construire son premier outil IA, ou écris-moi sur LinkedIn.